This article examines the most common statistic reported in scientific papers and used in applied statistical analyses – the p-value. The article goes through the definition illustrated with examples, discusses its utility, interpretation, and common misinterpretations of observed statistical significance and significance levels. It is structured as follows:
- p-value definition and meaning
- The utility of p-values and statistical significance
- p-value interpretation in outcomes of experiments (randomized controlled trials)
- p-value interpretation in regressions and correlations of observational data
- Misinterpretations of statistically significant p-values
- Misinterpretations of statistically non-significant outcomes
p-value definition and meaning
The technical definition of the p-value is (based on [4,5,6]):
A p-value is the probability of the data-generating mechanism corresponding to a specified null hypothesis to produce an outcome as extreme or more extreme than the one observed.
However, it is only straightforward to understand for those already familiar in detail with terms such as ‘probability’, ‘null hypothesis’, ‘data generating mechanism’, ‘extreme outcome’. These, in turn, require knowledge of what a ‘hypothesis’, a ‘statistical model’ and ‘statistic’ mean, and so on. While some of these will be explained on a cursory level in the following paragraphs, those looking for deeper understanding should consider consulting the following glossary definitions: statistical model, hypothesis, null hypothesis, statistic.
A slightly less technical and therefore more accessible definition is:
A p-value quantifies how likely it is to erroneously reject a specific statistical hypothesis, were it true, based on a given set of data.
Let us break these down and examine several examples to make both of these definitions make sense.
What does ‘p‘ in ‘p-value’ stand for?
p stands for probability where probability means the frequency with which an event occurs under certain assumptions. The most common example is the frequency with which a coin lands heads under the assumption that it is equally balanced (a fair coin toss). That frequency is 0.5 (50%).
Capital ‘P’ stands for probability in general, whereas lowercase ‘p‘ refers to the probability of a particular data realization. To expand on the coin toss example: P would stand for the probability of heads in general, whereas p could refer to the probability of landing a series of five heads in a row, or the probability of landing less than or equal to 38 heads out of 100 coin flips.
What does p measure and how to interpret it?
Given that it was established that p stands for probability, it is easy to figure out it measures a sort of probability.
In everyday language the term ‘probability’ might be used as synonymous to ‘chance’, ‘likelihood’, ‘odds’, e.g. there is 90% probability that it will rain tomorrow. However, in statistics one cannot speak of ‘probability’ without specifying a mechanism which generates the observed data. A simple example of such a mechanism is a device which produces fair coin tosses. A statistical model based on this data-generating mechanism can be put forth and under that model the probability of 38 or less heads out of 100 tosses can be estimated to be 1.05%, for example by using a binomial calculator. The p-value against the model of a fair coin would be ~0.01 (rounding it to 0.01 from hereon for the purposes of the article).
The way to interpret that p-value is: observing 38 heads or less out of the 100 tosses could have happened in only 1% of infinitely many series of 100 fair coin tosses. The null hypothesis in this case is defined as the coin being fair, therefore having a 50% chance for heads and 50% chance for tails on each toss.
Assuming the null hypothesis is true allows the comparison of the observed data to what would have been expected under the null. It turns out the particular observation of 38/100 heads is a rather improbable and thus surprising outcome under the assumption of the null hypothesis. This is measured by the low p-value which also accounts for more extreme outcomes such as 37/100, 36/100, and so on all the way to 0/100.
If one had a predefined level of statistical significance at 0.05 then one would claim that the outcome is statistically significant since it’s p-value of 0.01 meets the 0.05 significance level (0.01 ≤ 0.05). A visual representation of the relationship between p-values, significance level (p-value threshold), and statistical significance of an outcome is illustrated visually in this graph:
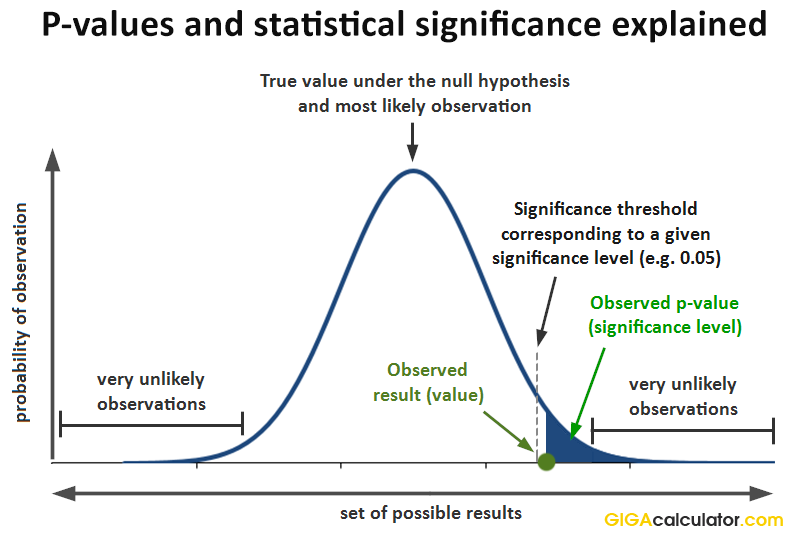
In fact, had the significance threshold been at any value above 0.01, the outcome would have been statistically significant, therefore it is usually said that with a p-value of 0.01, the outcome is statistically significant at any level above 0.01.
Continuing with the interpretation: were one to reject the null hypothesis based on this p-value of 0.01, they would be acting as if a significance level of 0.01 or lower provides sufficient evidence against the hypothesis of the coin being fair. One could interpret this as a rule for a long-run series of experiments and inferences. In such a series, by using this p-value threshold one would incorrectly reject the fair coin hypothesis in at most 1 out of 100 cases, regardless of whether the coin is actually fair in any one of them. An incorrect rejection of the null is often called a type I error as opposed to a type II error which is to incorrectly fail to reject a null.
A more intuitive interpretation proceeds without reference to hypothetical long-runs. This second interpretation comes in the form of a strong argument from coincidence:
- there was a low probability (0.01 or 1%) that something would have happened assuming the null was true
- it did happen so it has to be an unusual (to the extent that the p-value is low) coincidence that it happened
- this warrants the conclusion to reject the null hypothesis
(source). It stems from the concept of severe testing as developed by Prof. Deborah Mayo in her various works [1,2,3,4,5] and reflects an error-probabilistic approach to inference.
A p-value only makes sense under a specified null hypothesis
It is important to understand why a specified ‘null hypothesis’ should always accompany any reported p-value and why p-values are crucial in so-called Null Hypothesis Statistical Tests (NHST). Statistical significance only makes sense when referring to a particular statistical model which in turn corresponds to a given null hypothesis. A p-value calculation has a statistical model and a statistical null hypothesis defined within it as prerequisites, and a statistical null is only interesting because of some tightly related substantive null such as ‘this treatment improves outcomes’. The relationship is shown in the chart below:

In the coin example, the substantive null that is interesting to (potentially) reject is the claim that the coin is fair. It translates to a statistical null hypothesis (model) with the following key properties:
- heads having 50% chance and tails having 50% chance, on each toss
- independence of each toss from any other toss. The outcome of any given coin toss does not depend on past or future coin tosses.
- homogeneity of the coin behavior over time (the true chance does not change across infinitely many tosses)
- a binomial error distribution
The resulting p-value of 0.01 from the coin toss experiment should be interpreted as the probability only under these particular assumptions.
What happens, however, if someone is interested in rejecting the claim that the coin is somewhat biased against heads? To be precise: the claim that it has a true frequency of heads of 40% or less (hence 60% for tails) is the one they are looking to deny with a certain evidential threshold.
The p-value needs to be recalculated under their null hypothesis so now the same 38 heads out of 100 tosses result in a p-value of ~0.38 (calculation). If they were interested in rejecting such a null hypothesis, then this data provide poor evidence against it since a 38/100 outcome would not be unusual at all if it were in fact true (p ≤ 0.38 would occur with probability 38%).
Similarly, the p-value needs to be recalculated for a claim of bias in the other direction, say that the coin produces heads with a frequency of 60% or more. The probability of observing 38 or fewer out of 100 under this null hypothesis is so extremely small (p-value ~= 0.000007364 or 7.364 x 10-6 in standard form, calculation) that maintaining a claim for 60/40 bias in favor of heads becomes near-impossible for most practical purposes.
How to calculate a p-value?
A p-value can be calculated for any frequentist statistical test. Common types of statistical tests include tests for:
- absolute difference in proportions;
- absolute difference in means;
- relative difference in means or proportions;
- goodness-of-fit;
- homogeneity
- independence
- analysis of variance (ANOVA)
and others. Different statistics would be computed depending on the error distribution of the parameter of interest in each case, e.g. a t value, z value, chi-square (Χ2) value, f-value, and so on.
p-values can then be calculated based on the cumulative distribution functions (CDFs) of these statistics whereas pre-test significance thresholds (critical values) can be computed based on the inverses of these functions. You can try these by plugging different inputs in our critical value calculator, and also by consulting its documentation.
In its generic form, a p-value formula can be written down as:
p = P(d(X) ≥ d(x0); H0)
where P stands for probability, d(X) is a test statistic (distance function) of a random variable X, x0 is a typical realization of X and H0 is the selected null hypothesis. The semi-colon means ‘assuming’. The distance function is the aforementioned cumulative distribution function for the relevant error distribution. In its generic form a distance function equation can be written as:
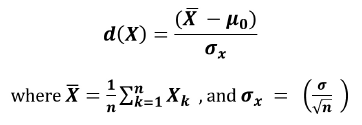
X-bar is the arithmetic mean of the observed values, μ0 is a hypothetical or expected mean to which X is compared, and n is the sample size. The result of a distance function will often be expressed in a standardized form – the number of standard deviations between the observed value and the expected value.
The p-value calculation is different in each case and so a different formula will be applied depending on circumstances. You can see examples in the p-values reported in our statistical calculators, such as the statistical significance calculator for difference of means or proportions, the Chi-square calculator, the risk ratio calculator, odds ratio calculator, hazard ratio calculator, and the normality calculator.
A practical example
A very fresh (as of late 2020) example of the application of p-values in scientific hypothesis testing can be found in the recently concluded COVID-19 clinical trials. Multiple vaccines for the virus which spread from China in late 2019 and early 2020 have been tested on tens of thousands of volunteers split randomly into two groups – one gets the vaccine and the other gets a placebo. This is called a randomized controlled trial (RCT). The main parameter of interest is the difference between the rates of infections in the two groups. An appropriate test is the t-test for difference of proportions, but the same data can be examined in terms of risk ratios or odds ratio.
The null hypothesis in many of these medical trials is that the vaccine is at least 30% efficient. A statistical model can be built about the expected difference in proportions if the vaccine’s efficiency is 30% or less, and then the actual observed data from a medical trial can be compared to that null hypothesis. Most trials set their significance level at the minimum required by the regulatory bodies (FDA, EMA, etc.), which is usually set at 0.05. So, if the p-value from a vaccine trial is calculated to be below 0.05, the outcome would be statistically significant and the null hypothesis of the vaccine being less than or equal to 30% efficient would be rejected.
Let us say a vaccine trial results in a p-value of 0.0001 against that null hypothesis. As this is highly unlikely under the assumption of the null hypothesis being true, it provides very strong evidence against the hypothesis that the tested treatment has less than 30% efficiency.
However, many regulators stated that they require at least 50% proven efficiency. They posit a different null hypothesis and so the p-value presented before these bodies needs to be calculated against it. This p-value would be somewhat increased since 50% is a higher null value than 30%, but given that the observed effects of the first vaccines to finalize their trials are around 95% with 95% confidence interval bounds hovering around 90%, the p-value against a null hypothesis stating that the vaccine’s efficiency is 50% or less is likely to still be highly statistically significant, say at 0.001. Such an outcome is to be interpreted as follows: had the efficiency been 50% or below, such an extreme outcome would have most likely not been observed, therefore one can proceed to reject the claim that the vaccine has efficiency of 50% or less with a significance level of 0.001.
While this example is fictitious in that it doesn’t reference any particular experiment, it should serve as a good illustration of how null hypothesis statistical testing (NHST) operates based on p-values and significance thresholds.
The utility of p-values and statistical significance
It is not often appreciated how much utility p-values bring to the practice of performing statistical tests for scientific and business purposes.
Quantifying relative uncertainty of data
First and foremost, p-values are a convenient expression of the uncertainty in the data with respect to a given claim. They quantify how unexpected a given observation is, assuming some claim which is put to the test is true. If the p-value is low the probability that it would have been observed under the null hypothesis is low. This means the uncertainty the data introduce is high. Therefore, anyone defending the substantive claim which corresponds to the statistical null hypothesis would be pressed to concede that their position is untenable in the face of such data.
If the p-value is high, then the uncertainty with regard to the null hypothesis is low and we are not in a position to reject it, hence the corresponding claim can still be maintained.
p-values as convenient summary statistics
As evident by the generic p-value formula and the equation for a distance function which is a part of it, a p-value incorporates information about:
- the observed effect size relative to the null effect size
- the sample size of the test
- the variance and error distribution of the statistic of interest
It would be much more complicated to communicate the outcomes of a statistical test if one had to communicate all three pieces of information. Instead, by way of a single value on the scale of 0 to 1 one can communicate how surprising an outcome is. This value is affected by any change in any of these variables.
Easy comparison of different statistical tests
This quality stems from the fact that assuming that a p-value from one statistical test can easily and directly be compared to another. The minimal assumptions behind significance tests mean that given that all of them are met, the strength of the statistical evidence offered by data relative to a null hypothesis of interest is the same in two tests if they have approximately equal p-values.
This is especially useful in conducting meta-analyses of various sorts, or for combining evidence from multiple tests.
p-value interpretation in outcomes of experiments
When a p-value is calculated for the outcome of a randomized controlled experiment, it is used to assess the strength of evidence against a null hypothesis of interest, such as that a given intervention does not have a positive effect. If H0: μ0 ≤ 0% and the observed effect is μ1 = 30% and the calculated p-value is 0.025, this can be used to reject the claim H0: μ0 ≤ 0% at any significance level ≥ 0.025. This, in turn, allows us to claim that H1, a complementary hypothesis called the ‘alternative hypothesis’, is in fact true. In this case since H0: μ0 ≤ 0% then H1: μ1 > 0% in order to exhaust the parameter space, as illustrated below:
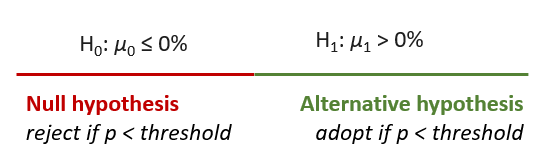
A claim as the above corresponds to what is called a one-sided null hypothesis. There could be a point null as well, for example the claim that an intervention has no effect whatsoever translates to H0: μ0 = 0%. In such a case the corresponding p-value refers to that point null and hence should be interpreted as rejecting the claim of the effect being exactly zero. For those interested in the differences between point null hypotheses and one-sided hypotheses the articles on onesided.org should be an interesting read. TLDR: most of the time you’d want to reject a directional claim and hence a one-tailed p-value should be reported [8].
These finer points aside, after observing a low enough p-value, one can claim the rejection of the null and hence the adoption of the complementary alternative hypothesis as true. The alternative hypothesis is simply a negation of the null and is therefore a composite claim such as ‘there is a positive effect’ or ‘there is some non-zero effect’. Note that any inference about a particular effect size within the alternative space has not been tested and hence claiming it has probability equal to p calculated against a zero effect null hypothesis (a.k.a. the nil hypothesis) does not make sense.
p–value interpretation in regressions and correlations of observational data
When performing statistical analyses of observational data p-values are often calculated for regressors in addition to regression coefficients and for the correlation in addition to correlation coefficients. A p-value falling below a specific statistical significance threshold measures how surprising the observed correlation or regression coefficient would be if the variable of interest is in fact orthogonal to the outcome variable. That is – how likely would it be to observe the apparent relationship, if there was no actual relationship between the variable and the outcome variable.
Our correlation calculator outputs both p-values and confidence intervals for the calculated coefficients and is an easy way to explore the concept in the case of correlations. Extrapolating to regressions is then straightforward.
Misinterpretations of statistically significant p-values
There are several common misinterpretations[7] of p-values and statistical significance and no calculator can save one from falling for them. The following errors are often committed when a result is seen as statistically significant.
Mistaking statistical significance with practical significance
A result may be highly statistically significant (e.g. p-value 0.0001) but it might still have no practical consequences due to a trivial effect size. This often happens with overpowered designs, but it can also happen in a properly designed statistical test. This error can be avoided by always reporting the effect size and confidence intervals around it.
Treating the significance level as likelihood for the observed effect
Observing a highly significant result, say p-value 0.01 does not mean that the likelihood that the observed difference is the true difference. In fact, that likelihood is much, much smaller. Remember that statistical significance has a strict meaning in the NHST framework.
For example, if the observed effect size μ1 from an intervention is 20% improvement in some outcome and a p-value against the null hypothesis of μ0 ≤ 0% has been calculated to be 0.01, it does not mean that one can reject μ0 ≤ 20% with a p-value of 0.01. In fact, the p-value against μ0 ≤ 20% would be 0.5, which is not statistically significant by any measure.
To make claims about a particular effect size it is recommended to use confidence intervals or severity, or both.
Treating p-values as likelihoods attached to hypotheses
For example, stating that a p-value of 0.02 means that there is 98% probability that the alternative hypothesis is true or that there is 2% probability that the null hypothesis is true. This is a logical error.
By design, even if the null hypothesis is true, p-values equal to or lower than 0.02 would be observed exactly 2% of the time, so one cannot use the fact that a low p-value has been observed to argue there is only 2% probability that the null hypothesis is true. Frequentist and error-statistical methods do not allow one to attach probabilities to hypotheses or claims, only to events[4]. Doing so requires an exhaustive list of hypotheses and prior probabilities attached to them which goes firmly into decision-making territory. Put in Bayesian terms, the p-value is not a posterior probability.
Misinterpretations of statistically non-significant outcomes
Statistically non-significant p-values – that is, p is greater than the specified significance threshold α (alpha), can lead to a different set of misinterpretations. Due to the ubiquitous use of p-values, these are committed often as well.
A high p-value means the null hypothesis is true
Treating a high p-value / low significance level as evidence, by itself, that the null hypothesis is true is a common mistake. For example, after observing p = 0.2 one may claim this is evidence that there is no effect, e.g. no difference between two means, is a common mistake.
However, it is trivial to demonstrate why it is wrong to interpret a high p-value as providing support for the null hypothesis. Take a simple experiment in which one measures only 2 (two) people or objects in the control and treatment groups. The p-value for this test of significance will surely not be statistically significant. Does that mean that the intervention is ineffective? Of course not, since that claim has not been tested severely enough. Using a statistic such as severity can completely eliminate this error[4,5].
A more detailed response would say that failure to observe a statistically significant result, given that the test has enough statistical power, can be used to argue for accepting the null hypothesis to the extent warranted by the power and with reference to the minimum detectable effect for which it was calculated. For example, if the statistical test had 99% power to detect an effect of size μ1 at level α and it failed, then it could be argued that it is quite unlikely that there exists and effect of size μ1 or greater as in that case one would have most likely observed a significant p-value.
Lack of statistical significance suggests a small effect size
This is a softer version of the above mistake wherein instead of claiming support for the null hypothesis, a low p-value is taken, by itself, as indicating that the effect size must be small.
This is a mistake since the test might have simply lacked power to exclude many effects of meaningful size. Examining confidence intervals and performing severity calculations against particular hypothesized effect sizes would be a way to avoid this issue.
References:
[2] Mayo, D.G. (1996). “Error and the Growth of Experimental Knowledge”. Chicago, Illinois: University of Chicago Press. DOI:10.1080/106351599260247
[4] Mayo, D.G., Spanos. A. (2011). “Error Statistics”. Vol. 7, in Handbook of Philosophy of Science Volume 7 – Philosophy of Statistics. Elsevier. 1-46.
[5] Mayo, D.G. (2018). “Statistical Inference as Severe Testing”. Cambridge: Cambridge University Press. ISBN: 978-1107664647
[6] Georgiev, G.Z. (2019). “Statistical Methods in Online A/B Testing”. ISBN: 978-1694079725

An applied statistician, data analyst, and developer of statistical software, Georgi has expertise in web analytics, statistics, design of experiments, and business risk management, among others. He covers a variety of topics where mathematical models and statistics are useful and loves to build calculators which solve apply these models in practice. Georgi is also the author of the influential book “Statistical Methods in Online A/B Testing” (2019).