Normality Calculator
Use this normality test calculator to easily assess if the normality assumption can be applied to your data by using a battery of mis-specification tests. Currently supports: Shapiro-Wilk test / Shapiro-Francia test (n < 50 / n > 50), Anderson-Darling test, Jarque & Bera test, Cramer-von Mises test, d'Agostino-Pearson test. Plots a histogram of the data with a normal distribution overlay.
- What is a normality test?
- Interpreting the outcome of tests for normality
- Supported tests
- The Shapiro-Wilk test / Shapiro-Francia test
- The Cramer-von Mises test
- The Anderson-Darling test
- The d'Agostino-Pearson test
- The Jarque & Bera test
- Practical examples
What is a normality test?
A test of normality in statistics and probability theory is used to quantify if a certain sample was generated from a population with a normal distribution via a process that produces independent and identically-distributed values. Normality tests can be based on the 3-rd and 4-th central moments (skewness and kurtosis), on regressions/correlations stemming from P-P and Q-Q plots or on distances defined using the empirical cumulative distribution functions (ecdf). The Null hypothesis can generally be stated as: "data can be modelled using the normal distribution", but since some normality tests also check if the data is independent and identically distributed (IID) a low p-value from these tests may be either due to a non-normal distribution or due to the IID assumption not holding. Separate tests for independence and heterogeneity can be performed to rule out those possibilities.
Tests for normality like the Shapiro-Wilk are useful since many widely used statistical methods work under the assumption of normally-distributed data and may require alteration in order to accommodate non-normal data. Using a statistical test designed under the assumption of Normal or NIID data when the data is not normal renders the statistical model inadequate and the results meaningless, regardless if one is dealing with experimental or observational data (regressions, correlations, etc.).
Normality tests such as those implemented in our normality test calculator should be run on the full data without removing any outliers, unless the reason for the outlier is known and its removal from the analysis as a whole can be readily justified (e.g. erroneously recorded data, data from source later proven to be unreliable, etc.).
Interpreting the outcome of tests for normality
The outcomes generated by our normality calculator consist of the p-value from each test and the test statistic (e.g. W, JB, K2). A lower p-value is a stronger signal for a discrepancy. Conventionally values under 0.05 are considered strong evidence for departure from normality (or IID, for some tests). Since the null is that the data is normal, the alternative is that it is not normal, but note that these tests do not point to a particular alternative distribution.
However, the opposite is not necessarily true: a high p-value, say 0.3, might be due to the low sensitivity of the test relative to the number of data points you have entered and the type of distribution. That said, with a sufficiently large sample size a high p-value can be treated as evidence for lack of discrepancy. See "Supported Tests" below for a brief discussion on the relative sensitivity of some of the tests.
With smaller sample sizes and/or distributions close to the normal it is expected to see some tests detect a departure from normality (very low p-values) while others show much higher p-values. This is most likely due to different sensitivity of the various tests towards different types and sizes of departures. If even a single mis-specification test results in a low p-value the normality assumption should be reconsidered, usually through re-specification. Switching to non-parametric tests is generally not recommended as it leads to loss of specificity and thus to more vague statistical inferences.
Supported tests
This online normality calculator currently supports the following tests: Shapiro-Wilk / Shapiro-Francia, Anderson-Darling, Cramer-von Mises, d'Agostino-Pearson and the Jarque & Bera test. The following tests are not supported since they have significantly inferior sensitivity: Kolmogorov-Smirnov test, Ryan-Joiner test, Lilliefors-van Soest test.
While most who want to check their data for normality would search for the Shapiro-wilk test online, Mbah & Paothong (2014) [1] demonstrate via a comparison of several of the most-widely used tests across nine of the most-popular tests for normality that the Shapiro-Francia test is generally the most powerful, followed by the Shapiro-Wilk test. The Anderson Darling test is most sensitive under certain conditions, followed by the D’Agostino and Pearson. The Jarque-Bera test outperforms all against several distributions but with considerably high sample sizes (hundreds of data points).
More on each of the supported tests below.
The Shapiro-Wilk test / Shapiro-Francia test
The Shapiro-Wilk test is a regression/correlation-based test using the ordered sample. It results in the W statistic which is scale and origin invariant and can thus test the composite null hypothesis of normality. It was devised in 1965 by Samuel Shapiro and Martin Wilk who tabulated linear coefficients for computing W for samples of up to 50 data points [2]. The test is consistent against all alternatives.
Shapiro in collaboration with Francia proposed an extension of the method for handling samples with more than 50 data points in 1972 [3]: the Shapiro-Francia test, which is what our Shapiro-Wilk test calculator uses automatically if you supply it with more than 50 data points. Some people incorrectly refer to this test as the Shapiro-Wilk test, but it is different and in fact performs better than the Shapiro-Wilk test as it is more sensitive against most distributions even for sample sizes smaller than 50 [1]. In computing the W statistic we employ the Royston method [4] with a maximum sample size of 5,000.
The test assumes a random sample and thus a violation of the IID assumption may result in a low p-value even if the underlying distribution is normal, therefore additional tests for independence and heterogeneity are recommended if only the Shapiro-Wilk or Shapiro-Francia test results in a p-value below the desired significance threshold.
The Cramer-von Mises test
The Cramer-von Mises goodness-of-fit test is based on the empirical distribution and an ordered statistic [5,6]. It is distribution-free (can be used for other distributions as well) omnibus test alternative to the Kolmogorov-Smirnov test (also ecdf-based). The p-value is based on the largest discrepancy between the empirical distribution and the hypothetical (normal, in this case) distribution.
In terms of power against commonly-encountered alternatives it doesn't shine compared to the rest of the test in our goodness-of-fit calculator, but it is still widely used.
The Anderson-Darling test
The Anderson-Darling normality test [7] is a modification of the Cramer-von Mises approach and is thus a distance-test based on the empirical cumulative distribution function and distribution-free in its generic form. Compared with the Cramer–von Mises distance, the Anderson–Darling distance places more weight on observations in the tails of the distribution. It shows decent sensitivity against a variety of distributions, most notably the Laplace and Uniform distribution.
The d'Agostino-Pearson test
The d'Agostino-Pearson test a.k.a. as the D'Agostino's K-squared test is a normality test based on moments [8]. More specifically, it combines a test of skewness and a test for excess kurtosis into an omnibus skewness-kurtosis test which results in the K2 statistic. Due to its reliance on moments this test is generally less powerful than the SW/SF tests above as it ignores not just the dependence between the moments themselves, but also any existing higher-order moments making it lose all power if a distribution is non-normal but shows little deviation in terms of skewness and kurtosis. However the test has really good power against data from a uniform distribution which is why we have included it.
The K2 statistic is only approximately Χ2-distributed due to the dependence between the two moments used so p-values may in fact be rough approximations at small sample sizes.
The Jarque & Bera test
The Jarque-Bera test [9] is another normality test based on moments our normality calculator supports. It is one of the simplest, combining the skewness and kurtosis into a single JB statistic which is asymptotically Χ2 distributed. This asymptotic property is why it performs poorly with small sample sizes, but can be the most sensitive test against a number of alternatives such as the uniform, logistic, Laplace and t-distribution given the sample size is in the hundreds or small thousands.
The Jarque-Bera test may have zero power to detect departures towards distributions with 0 skewness and kurtosis of 3 (excess kurtosis of 0) like the Tukey λ distribution for certain values of λ.
Practical examples
Let us see how the normality test calculator works in practice. Clicking on this link will reload the page with a set of example data in the tool and the results from the battery of normality tests supported. It should look something like so (the histogram was generated in an external tool):
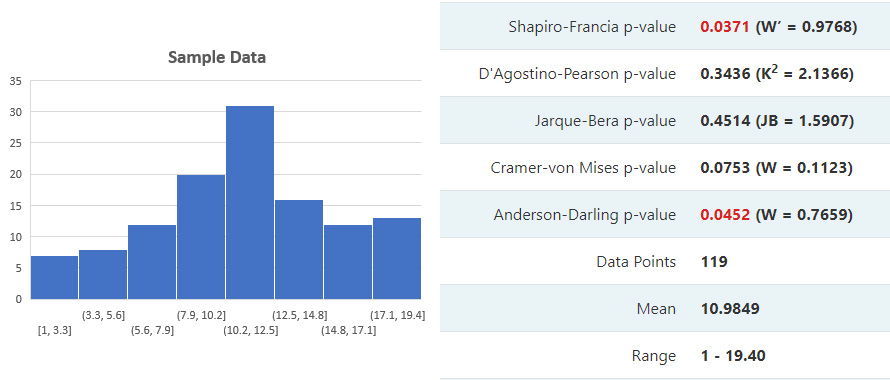
As we can see the data resembles normal, but it has a rather heavy right tail and two of the tests: the Shapiro-Francia and the Anderson-Darling are sensitive enough to infer this from the limited sample size. The Cramer-von Mises test with a p-value of 0.075 is a close third. Given these statistics we have more than enough evidence to rule out normality for most practical purposes and to seek a different distribution which more appropriately fits the empirical data. We might also want to check the independence and heterogeneity of the data.
References
Cite this calculator & page
Cite results from this online calculator or information on this page by choosing a citation format:
Georgiev, G.Z. (n.d.). Normality Calculator. GIGAcalculator.com. Retrieved Jul 30, 2026, from https://www.gigacalculator.com/calculators/normality-test-calculator.php
Our statistical calculators are featured in 400+ scientific papers (Google Scholar ) published in high-profile science journals by:











The author of this tool
 Georgi Georgiev is an applied statistician with background in statistical analysis of online controlled experiments, including developing statistical software, writing over one hundred articles and papers, as well as the influential book "Statistical Methods in Online A/B Testing".
Georgi Georgiev is an applied statistician with background in statistical analysis of online controlled experiments, including developing statistical software, writing over one hundred articles and papers, as well as the influential book "Statistical Methods in Online A/B Testing".