Z-score to P-value Calculator
Use this Z to P calculator to easily convert Z-scores to P-values (one or two-tailed) and see if a result is statistically significant. Z-score to percentile calculator (p-value from Z score) for both one-sided and two-sided p-values.
- Using the z-score to p-value calculator
- What is a "p-value"
- How to interpret a low p-value (statistically significant result)
- Common misinterpretations of p-values
- Z score to P-value conversion table
- One-tailed vs. two-tailed p-values
Using the z-score to p-value calculator
If you obtained a Z-score statistic from a given set of data and want to convert it to its corresponding p-value (percentile), this Z to P calculator is right for you. Just enter the Z-score that you know and choose the type of significance test: one-tailed or two-tailed to calculate the corresponding p-value using the normal CPDF (cumulative probability density function of the normal distribution). If you want to make directional inferences (say something about the direction or sign of the effect), select one-tailed, which corresponds to a one-sided composite null hypothesis. If the direction of the effect does not matter, select two-tailed, which corresponds to a point null hypothesis.
Since the normal distribution is symmetrical, it does not matter if you are computing a left-tailed or right-tailed p-value: just select one-tailed and you will get the correct result for the direction in which the observed effect is. If you want the p-value for the other tail of the distribution, just subtract it from 1.
What is a "p-value"
The p-value is used in the context of a Null-Hypothesis statistical test (NHST) and it is the probability of observing the result which was observed, or a more extreme one, assuming the null hypothesis is true 1. It is essentially the proportional area of the Z distribution cut off at the point of the observed Z score. In notation this is expressed as:
p(x0) = Pr(d(X) > d(x0); H0)
where x0 is the observed data (x1,x2...xn), d is a special function (statistic, e.g. calculating a Z-score), X is a random sample (X1,X2...Xn) from the sampling distribution of the null hypothesis. This can be visualized in this way:
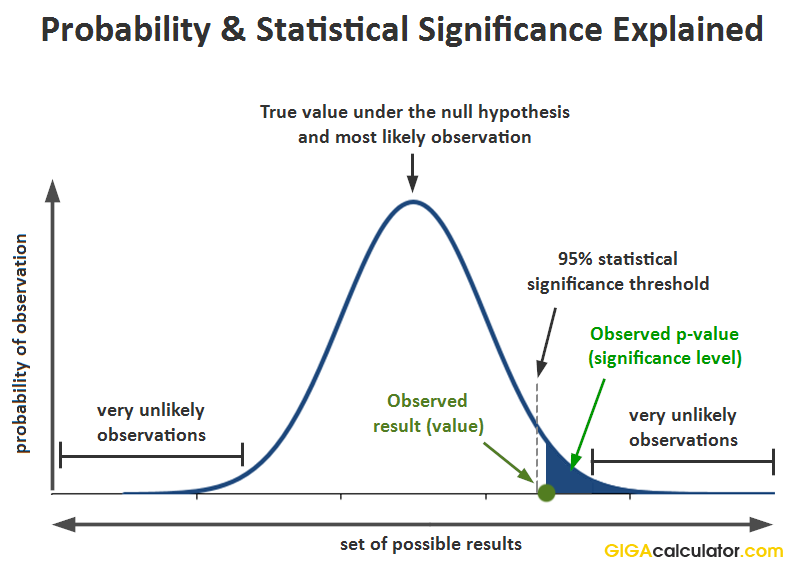
In terms of possible inferential errors, the p-value expresses the probability of committing a type I error: rejecting the null hypothesis if it is in fact true. The p-value is a worst-case bound on that probability. The p-value can be thought of as a percentile expression of a standard deviation measure, which the Z-score is, e.g. a Z-score of 1.65 denotes that the result is 1.65 standard deviations away from the arithmetic mean under the null hypothesis. Therefore, one can think of the p-value as a more user-friendly expression of how many standard deviations away from the normal a given observation is.
How to interpret a low p-value (statistically significant result)
Saying that a result is statistically significant means that the p-value is below the evidential threshold decided for the test before it was conducted. For example, if observing something which would only happen 1 out of 20 times if the null hypothesis is true is considered sufficient evidence to reject the null hypothesis, the threshold will be 0.05. In such a case, observing a p-value of 0.025 would mean that the result is statistically significant.
Let us examine what inferences are warranted when seeing a result which was quite improbable if the null was true. Observing a low p-value can be due to one of three reasons [2]:
- There is a true effect from the tested treatment or intervention.
- There is no true effect, but we happened to observe a rare outcome. The lower the p-value, the rarer (less likely, less probable) the outcome.
- The statistical model is invalid (does not reflect reality).
Obviously, one can't simply jump to conclusion 1.) and claim it with one hundred percent certainty, as this would go against the whole idea of the p-value. In order to use the p-value as a part of a decision process you need to consider external factors, which are a part of the experimental design process, which includes deciding on the significance threshold, sample size and power (power analysis), and the expected effect size, among other things.
If you are happy going forward with this much (or this little) uncertainty as is indicated by the p-value, then you have quantifiable guarantees related to the effect and future performance of whatever you are testing. For a deeper take on the p-value meaning, interpretation, and common misinterpretations, see our article on the p-value in statistics.
Common misinterpretations of p-values
There are several common misinterpretations of p-values and statistical significance and no calculator can save you from falling for them. The most common errors are mistaking a low p-value with evidence for lack of effect or difference, mistaking statistical significance with practical significance, as well as treating the p-value as a probability, related to a hypothesis, e.g. a p-value of 0.05 means that the probability the null hypothesis is true is 5%, or that the probability that the alternative hypothesis is true is 95%. >More details about these misinterpretations.
Z score to P-value conversion table
Below are some commonly encountered standard scores and their corresponding p-values and percentiles, assuming a one-tailed hypothesis.
| Standard score (Z) | P-value | Percentile |
|---|---|---|
| 0.8416 | 0.2000 | 80% |
| 1.2816 | 0.1000 | 90% |
| 1.6449 | 0.0500 | 95% |
| 1.9600 | 0.0250 | 97.5% |
| 2.0537 | 0.0200 | 98% |
| 2.3263 | 0.0100 | 99% |
| 3.0902 | 0.0010 | 99.9% |
| 3.2905 | 0.0005 | 99.95% |
The above table can be used to obtain a p-value from z-score for some values of Z, but for accurate results a calculator like ours which uses the normal distribution CDF to compute exact p-values is indispensible.
One-tailed vs. two-tailed p-values
There are wide-spread misconceptions about one-tailed and two-tailed tests, often referred to as one-sided and two-sided hypotheses, and their corresponding p-values [4]. This is not surprising given that even the Wikipedia article on the topic gets it wrong by stating that one-sided tests are appropriate only if "the estimated value can depart from the reference value in just one direction". Consequently, people often prefer two-sided tests due to the believe that using one-tailed tests results in bias, and/or higher than nominal error rates (type I errors), as well as that it involves more assumptions (about the direction of the effect).
Nothing could be further from the truth. There is no practical or theoretical situation in which a two-tailed test is appropriate since for it to be appropriate, the inference drawn or action taken has to be the same regardless of the direction of the effect of interest. That is never the case.
"A two-sided hypothesis and a two-tailed test should be used only when we would act the same way, or draw the same conclusions, if we discover a statistically significant difference in any direction." [3]. Doing otherwise leads to a host of issues, including reporting higher error rates than actual, and uncontrolled type III errors.
On the other hand, "A one-sided hypothesis and a one-tailed test should be used when we would act a certain way, or draw certain conclusions, if we discover a statistically significant difference in a particular direction, but not in the other direction." [5] which describes all practical and scientific applications of p-values and tests of significance in general. If you carefully formulate your hypotheses, you will find that you always want to state something about the direction of the null and alternative hypothesis, meaning you want to to get a one-sided p-value from a z score.
So, not only do one-tailed tests answer the question you are actually asking, but they are also more efficient, assuming the same significance threshold is used, resulting in %20-%60 faster experiments [3]. There is no good reason to use two-tailed tests as this results in 20-60% slower tests that answer a question one did not ask. A more in-depth reading and explanations: One-tailed vs Two-tailed Tests of Significance and reference #3 below. When obtaining a p-value from a z-score, it is important to choose the correct null hypothesis - one-sided or point null, depending on circumstances, and in most cases the correct p-value would be the one-sided / one-tailed one.
References
1Fisher R.A. (1935). "The Design of Experiments". Edinburgh: Oliver & Boyd.
5Spanos A. (2019). "Probability Theory and Statistical Inference". Cambridge University Press. pp. 396-404, doi: 10.1017/9781316882825
Cite this calculator & page
Cite results from this online calculator or information on this page by choosing a citation format:
Georgiev, G.Z. (n.d.). Z-score to P-value Calculator. GIGAcalculator.com. Retrieved Jul 02, 2026, from https://www.gigacalculator.com/calculators/z-score-to-p-value-calculator.php
Our statistical calculators are featured in 400+ scientific papers (Google Scholar ) published in high-profile science journals by:











The author of this tool
 Georgi Georgiev is an applied statistician with background in statistical analysis of online controlled experiments, including developing statistical software, writing over one hundred articles and papers, as well as the influential book "Statistical Methods in Online A/B Testing".
Georgi Georgiev is an applied statistician with background in statistical analysis of online controlled experiments, including developing statistical software, writing over one hundred articles and papers, as well as the influential book "Statistical Methods in Online A/B Testing".